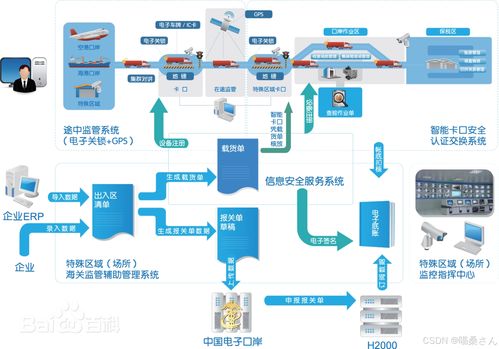
在2025年AICon全球人工智能開發與應用大會深圳站的舞臺上,一場題為《以卓越性價比釋放開放大模型潛能:TPU上的推理優化全解》的技術分享,聚焦于當前人工智能應用軟件開發的核心挑戰與前沿突破。隨著開源大模型的蓬勃發展,如何經濟高效地將其部署于實際應用,已成為產業界關注的焦點。本次分享系統性地拆解了在谷歌TPU(張量處理單元)這一專用硬件上,進行大模型推理優化的完整技術路徑與實踐策略。
核心內容首先剖析了開放大模型在推理階段面臨的主要瓶頸:巨大的計算量、內存帶寬壓力以及響應延遲。TPU憑借其針對矩陣運算的高度定制化設計,在處理這類負載時具有先天架構優勢。要充分發揮其“卓越性價比”,需要從模型、編譯器、運行時到系統層的全棧協同優化。
分享重點詳解了三大優化維度:
- 模型層壓縮與適配:探討了適用于TPU架構的模型量化技術(如INT8、FP16混合精度)、知識蒸餾以及輕量化網絡結構選擇,旨在減少模型參數量和計算復雜度,同時最小化精度損失。
- 編譯器與圖優化:深入介紹了針對TPU的XLA編譯器優化。通過操作融合、內存布局優化、常量折疊等技術,將模型計算圖轉換為在TPU上執行效率最高的形式,顯著減少內核啟動開銷和內存訪問次數。
- 運行時與部署策略:講解了批處理優化、動態批尺寸調整、請求排隊與調度策略,以提升硬件利用率。覆蓋了多芯片模型并行、流水線并行等分布式推理技術,以支持超大規模模型的部署。
演講結合了具體的性能基準測試與成本分析案例,量化展示了經過全棧優化后,在TPU上運行主流開源大模型所能實現的吞吐量提升與單位成本下降,為開發者提供了清晰的性價比提升路線圖。
本次AICon分享為人工智能應用軟件開發人員提供了一套在TPU硬件上釋放開放大模型潛能的實戰工具箱。它強調,性價比的卓越并非單一技術的神話,而是源于對從算法到硬件的整個執行棧的深刻理解與精細調優。隨著工具鏈的日益成熟,以可控的成本駕馭強大的人工智能模型,正加速從實驗室走向千行百業的海量應用場景。